
GPUによる並列化 Cuda利用

の続編です。下図(再掲)で、
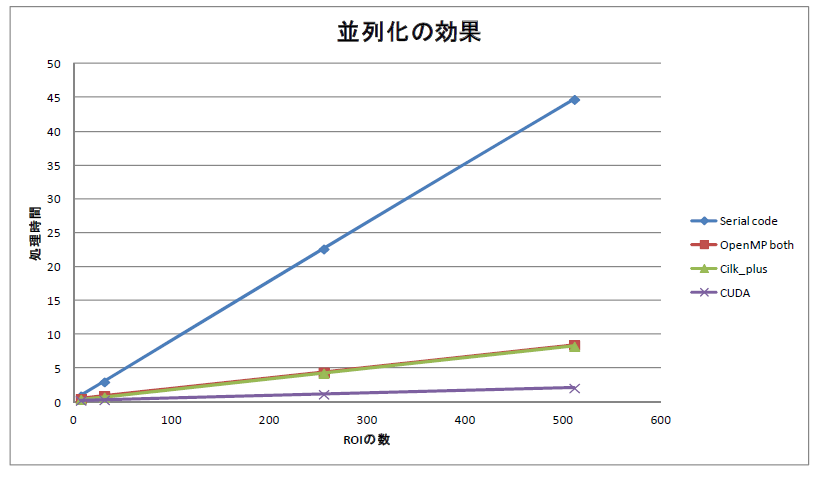
このグラフで一番高速なものです。CPU側でGPU上のコードを呼び出しているのは、下記のspiralprod(maxpos)です。
for( int frame = astart ; frame < aend ; frame++ ){
//cuda_spiral(frame,roinum); // prallel processing on roinum and 1024
//cuda_max(roinum); // max detection from
//plot_max(roinum);
setwork(workxs,workys,workxe,workye);
selected->setcurrent(frame);
selected->dispaframe(IDC_pict);
spiralprod(maxpos);
で下記のGPU側のコードでの、<<<grid,blk>>>という独特の呼び出し方ですが、原理的には動画ファイルから1フレーム読み込み、そのイメージをGPUに転送し、GPU側でspiral searchして、得られた結果をまたCPU側へ戻すということをやっています。それでもCPUよりも20倍高速です。
#include "book.h"
//#include "cutil.h"
//#include "cuprintf.cu"
/*
extern struct templat {
unsigned char* buffer;
float ave;
float norm;
int size;
} templates[512];
*/
//unsigned char** device_templatebuffer;
float* device_ave;
float* device_norm;
unsigned char* device_image;
unsigned char* device_baseimage;
short* device_maxpos;
float* device_results;
int* launched;
__constant__ short deltax[1024];
__constant__ short deltay[1024];
__constant__ short workxs[512],workxe[512],workys[512],workye[512];
__constant__ short templatesxs[512],templatesxe[512],templatesys[512],templatesye[512];
void settemplat(short* xs, short* ys, short* xe, short* ye)
{
HANDLE_ERROR(cudaMemcpyToSymbol(templatesxs,xs,sizeof(short)*512));
HANDLE_ERROR(cudaMemcpyToSymbol(templatesxe,xe,sizeof(short)*512));
HANDLE_ERROR(cudaMemcpyToSymbol(templatesys,ys,sizeof(short)*512));
HANDLE_ERROR(cudaMemcpyToSymbol(templatesye,ye,sizeof(short)*512));
}
void setwork(short* xs, short* ys, short* xe, short* ye)
{
HANDLE_ERROR(cudaMemcpyToSymbol(workxs,xs,sizeof(short)*512));
HANDLE_ERROR(cudaMemcpyToSymbol(workxe,xe,sizeof(short)*512));
HANDLE_ERROR(cudaMemcpyToSymbol(workys,ys,sizeof(short)*512));
HANDLE_ERROR(cudaMemcpyToSymbol(workye,ye,sizeof(short)*512));
}
void settable( short* x, short* y)
{
HANDLE_ERROR(cudaMemcpyToSymbol(deltax,x,sizeof(short)*1024));
HANDLE_ERROR(cudaMemcpyToSymbol(deltay,y,sizeof(short)*1024));
}
void initimagebuf(void)
{
HANDLE_ERROR(cudaMalloc((void **)&device_image,512*512));
HANDLE_ERROR(cudaMalloc((void **)&device_baseimage,512*512));
HANDLE_ERROR(cudaMalloc((void **)&device_results,512*1024*sizeof(float))); // results[512][1024]
HANDLE_ERROR(cudaMalloc((void **)&device_maxpos,512*sizeof(short)));
}
void setmisc(float* resul, short* maxpos)
{
HANDLE_ERROR(cudaMemcpy(device_results,resul,512*1024*sizeof(float),cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMemcpy(device_maxpos,maxpos,512*sizeof(short),cudaMemcpyHostToDevice));
}
void setbaseimage(unsigned char * src)
{
HANDLE_ERROR(cudaMemcpy(device_baseimage,src,512*512*1,cudaMemcpyHostToDevice));
}
void setimage(unsigned char * src)
{
HANDLE_ERROR(cudaMemcpy(device_image,src,512*512*1,cudaMemcpyHostToDevice));
}
__global__ void cuda_spiral(unsigned char* basepage,unsigned char* target,float* results)
{
int offset = threadIdx.x+256*blockIdx.y;
int nrect = blockIdx.x;
short width,height;
int x2,y2;
int x1s,x1e,x2s,x2e,y1s,y1e,y2s,y2e;
float val1,val2;
float term1,term2,term3,term4,term5;
float upper,lower;
x2s = workxs[nrect] + deltax[offset];
x2e = workxe[nrect] + deltax[offset];
y2s = workys[nrect] + deltay[offset];
y2e = workye[nrect] + deltay[offset];
width = x2e - x2s;
height = y2e - y2s;
term1 = term2 = term3 = term4 = term5 = 0;
float size = (float)width*(float)height;
x2 = x2s;
y2 = y2s;
x1s = templatesxs[nrect];
x1e = templatesxe[nrect];
y1s = templatesys[nrect];
y1e = templatesye[nrect];
for( int y = y1s ; y < y1e ; y++ ){
x2 = x2s;
for( int x = x1s ; x < x1e ; x++ ){
val1 = (float)basepage[y*512+x] ;
val2 = (float)target[y2*512+x2] ;
term1 += val1*val2;
term2 += val1;
term3 += val2;
term4 += val1*val1;
term5 += val2*val2;
x2++;
}
y2++;
}
term1 *= size;
upper = term1 - term2*term3;
lower = (size*term4 - term2*term2)*(size*term5 - term3*term3);
lower = sqrt(lower);
//results[roinum*1024+offset] = upper/lower;
results[nrect*1024+offset] = upper/lower;// was results[nrect][offset] nrect = 0 to 511 offset = 0 to 1023
}
__global__ void cuda_max(float* results,short* maxpos,int* lau)
{
int pos = blockIdx.x;
int maxp = 0;
float maxvalue = 0.0;
*lau = 1;
for( int k = 0 ; k < 1024 ; k++ ){
if( results[pos*1024+k] > maxvalue ){
maxp = k;
maxvalue = results[pos*1024+k];
}
}
maxpos[pos] = maxp;
//cuPrintf("pos %d\n",pos);
}
void spiralprod(short* to)
{
extern int roinum;
dim3 grid(roinum,4);
dim3 blk(256);
dim3 maxgrid(roinum);
dim3 maxthd(1);
int launch = 0;
//printf("calling kernels\n");
HANDLE_ERROR(cudaMalloc((void **)&launched,sizeof(int)));
HANDLE_ERROR(cudaMemcpy(launched,&launch,sizeof(int),cudaMemcpyHostToDevice));
//cudaPrintfInit();
//cudaPrintfDisplay(stdout, true);
cuda_spiral<<<grid,blk>>>(device_baseimage,device_image,device_results);
cudaError_t err = cudaGetLastError();
if( cudaSuccess != err) {
fprintf(stdout, "Cuda error: in file '%s' in line %i : %s.\n",
__FILE__, __LINE__, cudaGetErrorString( err) );
}
launch = 0;
HANDLE_ERROR(cudaMemcpy(launched,&launch,sizeof(int),cudaMemcpyHostToDevice));
cuda_max<<<maxgrid,maxthd>>>(device_results,device_maxpos,launched);
err = cudaGetLastError();
if( cudaSuccess != err) {
fprintf(stdout, "Cuda error: in file '%s' in line %i : %s.\n",
__FILE__, __LINE__, cudaGetErrorString( err) );
}
HANDLE_ERROR(cudaMemcpy(&launch,launched,sizeof(int),cudaMemcpyDeviceToHost));
//printf("cuda max %s\n",launch?"launched":"failed");
//cudaPrintfEnd();
HANDLE_ERROR(cudaMemcpy(to,device_maxpos,sizeof(short)*512,cudaMemcpyDeviceToHost));
//cudaPrintfEnd();
}
void getresults(float* to)
{
HANDLE_ERROR(cudaMemcpy(to,device_results,sizeof(float)*512*1024,cudaMemcpyDeviceToHost));
}
既出のOpenMPを使う並列化に比べると、かなり可読性低いです。それを改善したOpenACCという仕組みが出てきていますけど、あまり普及してないようです。OpenACCは、
最近ではIntelさんは、OneAPIとか言ってますが、どこまでの部分がGPGPUなのかが筆者はよく分かりません。GPUを使って並列化をすると確かにプログラムの高速化が実現できますが、そのチューニング方法、限界値の見極め等々色々と問題があると感じています。C++ Builder CEでcudaを使うこともできなくはないようですが、なにせCopilot君が示唆することなので、精査してから別記事で。
コメント