
開発系をVisual C++ with Intel Compiler ICCに移行

この記事の続編です。C++ Builderでの開発で、特にその処理速度が頭打ちであり、並列化によってさらなる高速化を目指す方向に進むために、Visual C++に開発系を切り替えました。新しいプログラムは、機能をトレースのみとして、そのスループットを計りました。その外観が、
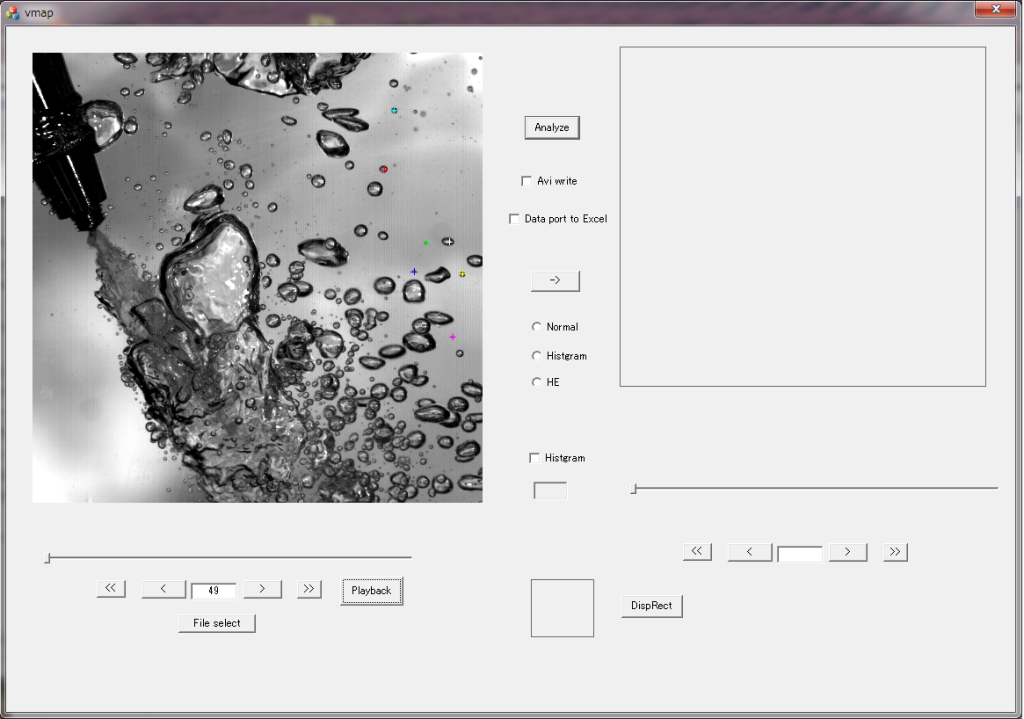
これになります。まずCPUのスレッドをフルに活用して並列化して高速化するわけですが、今お使いのWindowsマシンのCPUのコア数やスレッド数を調べるのは、CPU-Z
というユーティリティーで可能です。今この記事を書いているマシンで起動すると、
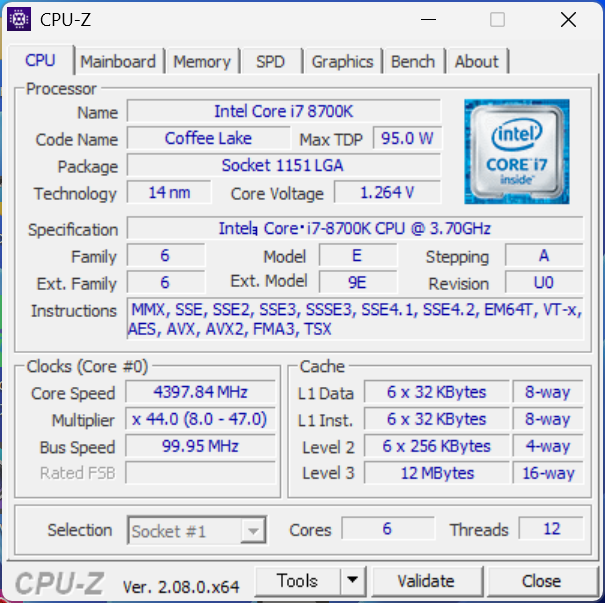
下の方に、Cores 6 さらに Threads 12とありますから、コアが6個で、Intelのハイパースレッドテクノロジーで、1コアにつき2個のスレッドを走らせられますから、トータル12個のスレッドが使えます。が、それは物理的に使える最大数のコアないしスレッド数なので、”目一杯働かせる”ためにはそれなりの仕組みが必要です。上のプロセッサが古いって?筆者のマシンのなかで比較的新しめのCPUでは、
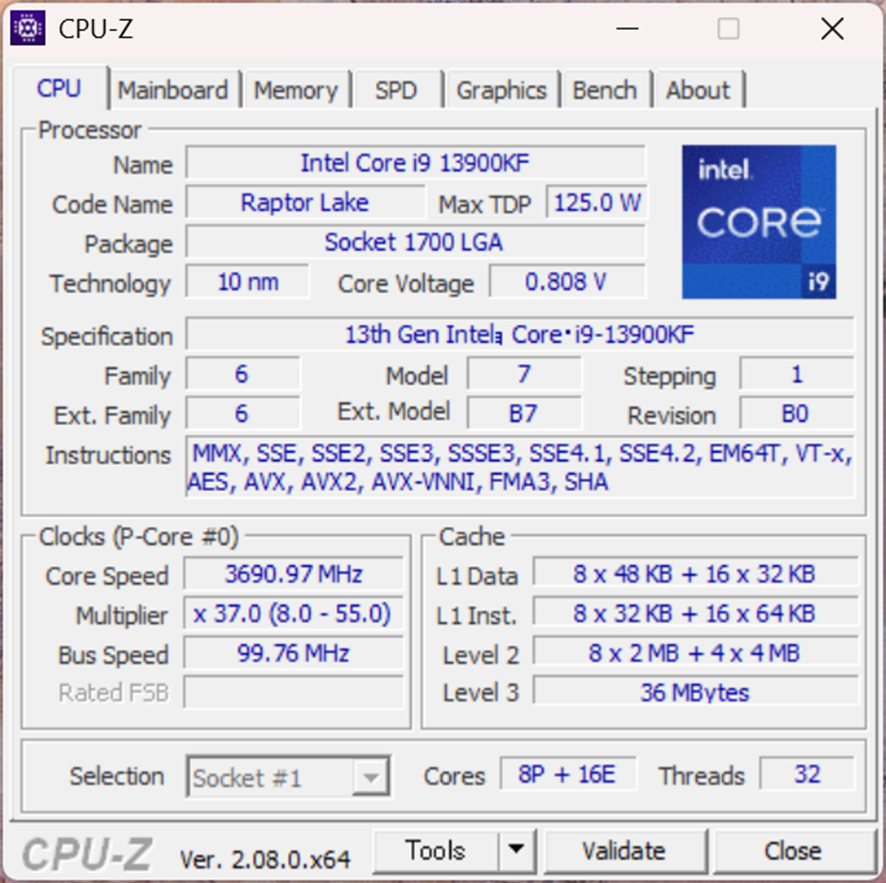
こんな感じです。スレッド数は32まで増えています。比較的簡単でメンテナンスも容易な手法としては、OpenMPという並列化テクニックがあります。ループを並列に走るスレッドに分けて、並走させ、時間を短縮するやり方です。下記のように重たいループの前に、キーワード
#pragma omp parallel forを入れるだけで、OpenMPをアクティブにしなければシリアルな処理になりますので、このpragmaディレクティブの有効、無効だけでシリアルなコードとパラレルなコードを使い分けることができます。
spiralsearch::spiralsearch(roi& templa ,CRect& start)
{
limit = 1000; // for now
maxcorrval = 0;
//CRect next;
double tempvalue;
int width;
int height;
//roi* c;
width = selected->getframerect().Width();
height = selected->getframerect().Height();
curr = check;
#pragma omp parallel for
//corrvalues[0] = 0.0; // special case
for( int x = 0 ; x < 1000 ; x++ ){
int xpos;
int ypos;
//next += spiral[x];
CRect next = start + spiral[x];
try {
roi* c = new roi(next);
xpos = (next.left+next.right)/2;
ypos = (next.top+next.bottom)/2;
//selected->disparect(*c,IDC_pict);
//basedlg->DispRoi(*c);
corrvalues[x] = templa*(*c);
//results[ypos*width+xpos] = corrvalues[x];
delete c;
}
catch( CMemoryException& e) {
TRACE("new roi error trapped");
exit(1);
}
//delete c;
}
for( int x = 1 ; x < 1000 ; x++ ){
if( corrvalues[x] > maxcorrval ){
maxcorrval = corrvalues[x];
maxdelta = x;
maxrect = start + spiral[x];
}
}
//TRACE("%d:max at spiral %d\n",targetframe,maxdelta);
//__itt_pause();
}
このプログラムは、MFCのダイアログベースのものですが、比較的単純なUIならばC++ Builder程簡単ではありませんが、充分作れます。ちなみにVisual C++はかなり昔からOpenMPが使えましたが、コンパイラをIntelのものに替えるとそれだけでさらに実行速度があがります。ま、Intelさんに取っては並列性も含めてプロセッサの性能を最大限に引き出せないと死活問題ですからね。
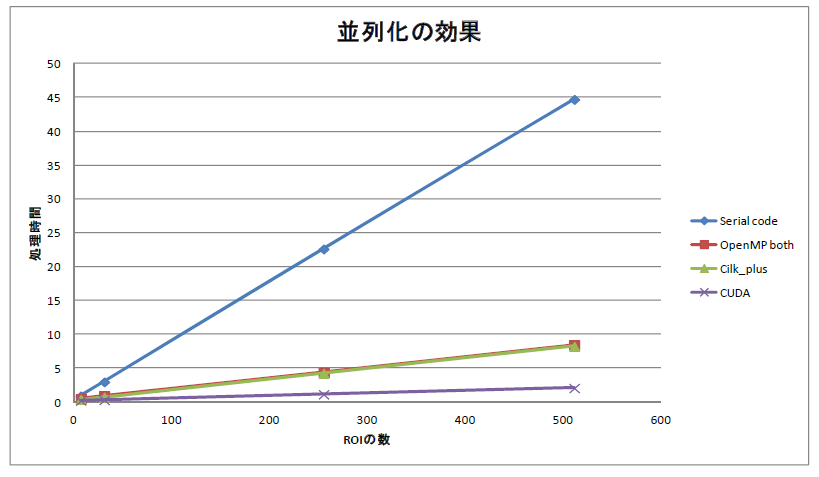
並列化の効果を示したのが、上図です。OpenMPとかCilk_plusとかでの高速化でトレース時間はシリアルコード(並列化を全くしない)の1/6くらいに短縮されおり、一定の効果が出ています。がグラフをよく見ると、CUDAというのがありさらに高速化できるのですが、それは機会を改めて書きますが、CPUではなくGPUによる並列化です。
コメント